After what felt like a long time, but in hindsight was rather quick, I'm proud to annouce the first release of Site Quality Crawler, a small project to help better understand one's web site. This project was put together by Mateusz Bocian and myself in our free time over the past few months, and while we've still got some features ahead, we both feel that it's valueable as is and is ready for a first public release.
The project can be found at the Site Quality Crawler GitHub Page and includes a reasonable readme page for users.
The gist of the project, once you've got everything up and running, is that you can crawl a site of your choosing from your local machine, and in return you'll get a comprehensive JSON report that can be analyzed and visualized offline.
Here is the output of the project running against this blog.
Landing Page
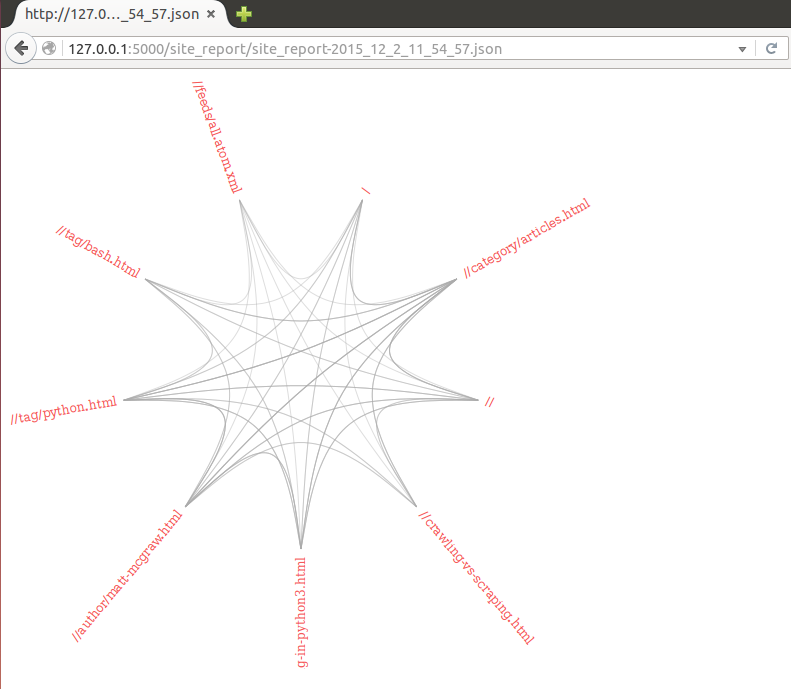
Visualization
JSON Report
[
{
"status_code": 200,
"url": "//author/matt-mcgraw.html",
"redirects": 1,
"id": "b21aee715d03e0a4c2cfb9b3e6bcd010",
"page_links": [
"7e01089e9786f86100efc3a3a7e57e32",
"7ab609b82cb46a316f8d75d4b73c7061",
"8fe2eb9fdda394b582640b20484e6484",
"b21aee715d03e0a4c2cfb9b3e6bcd010",
"7ab609b82cb46a316f8d75d4b73c7061",
"db1e0a77740647c0ad374e0fafe3f958",
"a463d47c75e308e00a7eeb68fd578251",
"b21aee715d03e0a4c2cfb9b3e6bcd010",
"7ab609b82cb46a316f8d75d4b73c7061",
"e0335caffb2071f708b02e4660d22906",
"db1e0a77740647c0ad374e0fafe3f958",
"a463d47c75e308e00a7eeb68fd578251",
"f9b7867c4135625cc844803b533bace6"
]
},...
]
Unfortunately you must clone the repository in order to use the project, but we'll be looking into making it available through pip sometime in the coming months. Please feel free to reach out to me on github if you have any questions or comments.